
Causality meets reality: CausalVerse gives AI a harder, fairer test
Wednesday, December 03, 2025

A lot of modern AI can spot patterns such as cats in photos, trends in dashboards, and familiar phrases in text. Far fewer systems can explain why those patterns arise, or predict what will happen when you intervene. That skill of figuring out causes rather than correlations is the ambition of causal representation learning (CRL).
In practice, it means recovering the hidden variables and relationships that actually generate the data, not just the surface-level regularities. But CRL research has had a nagging problem: we haven’t had a testbed that is both realistic and precise enough to say whether a method really learned the right causes. You either got toy physics setups with perfect ground truth but little realism, or you got real data with impressive visuals but no way to check if the model recovered the true causal story.
A NeurIPS 2025 paper from MBZUAI tries to end that stalemate with CausalVerse, a large, open benchmark that marries high-fidelity visual complexity with full access to the underlying causal variables and graphs.
“There have been many exciting theoretical advances in causal representation learning in recent years,” says lead author and research scientist, Guangyi Chen. “Despite these impressive results, the applicability of these methods to complex real-world problems has not been well tested. To make causal representation learning both practical and powerful, we believe that developing a reliable testbed is a crucial first step.”
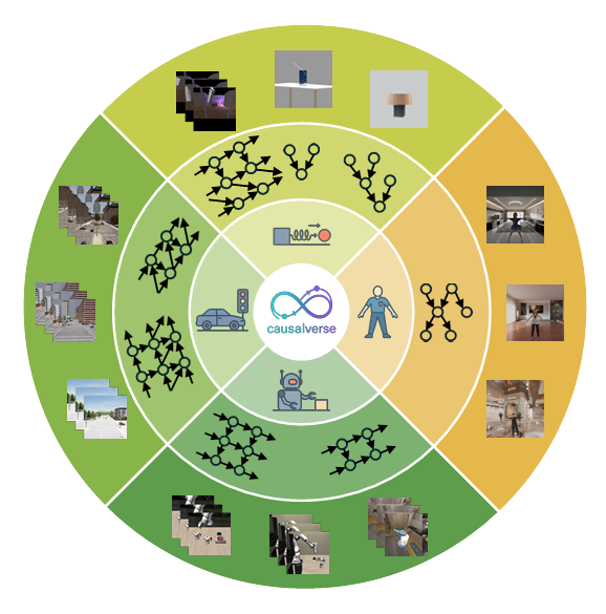
Substantial scale and multiple settings
At heart, CausalVerse is a suite of configurable simulations rendered with the tools used for games and robotics prototypes, so the visuals look and behave like the messy world models will face. The scale is substantial: roughly 200,000 images and 300 million video frames, spread across 24 sub-scenes in four domains that together cover both static and dynamic settings: static image generation, dynamic physical simulations, robotic manipulation, and traffic situations.
Each scene is built on a causal graph, complete with the latent variables that drive it, so researchers can directly compare the learned features with ground truth causal factors, instead of guessing from downstream accuracy. The benchmark is organized hierarchically (from domain to scene to instance), which makes it easy to vary complexity in a controlled way, from a single object under changing illumination to multi-agent traffic interactions with competing goals.

The realism–rigor tension that has hampered CRL is explicit in the paper’s motivation. Prior synthetic datasets let you verify identifiability, but they rarely look like the world and often top out at a handful of latent factors. Real-world evaluations lean on indirect proxies (domain generalization, transfer, reasoning) but with no ground truth they can’t reveal whether a model recovered “the right” factors or just latched onto correlations that happened to work for that task.
CausalVerse tries to deliver both: lifelike scenes and gold-standard causal labels, plus the option to reconfigure the causal structure and interventions so you can evaluate methods under their preferred assumptions or stress-test them when those assumptions don’t hold. That flexibility is a big deal: if your theory needs multiple distinct “views” or particular temporal patterns, you can generate exactly that; if you want to see how robust a method is when those conditions fail, you can generate that, too.
When asked about the most surprising findings when writing the paper, Guangyi says: “We found that the resolution of objects poses a critical challenge for the final results. This suggests that many factors may influence the performance of causal representation learning in real-world settings, highlighting substantial room for improvement and further investigation.”
From static scenes to dynamic worlds
For an AI researcher, the variety of causal challenges on offer matters as much as the scale. The dynamic physics scenes range from aggregated single-frame depictions (e.g., a cylinder compressing a spring or light refracting through media) to full temporal trajectories (falls, projectile motion, single- and multi-object collisions). Robotics scenes cover manipulation and navigation with sequential dependence and contact dynamics. Traffic scenes model multi-agent interactions in varied cities, weather, and densities, where tiny changes in one actor’s behavior can ripple into accidents or smooth merges, exactly the kind of intervention-driven phenomena CRL claims to capture. Latent dimensionality runs from a handful of global factors to hundreds of per-frame variables in the temporal domains (positions, orientations, velocities), so methods that only work in low-dimensional toy worlds get a candid stress test.
CausalVerse also standardizes how to measure whether a method actually recovers causes. The benchmark reports component-wise identifiability via the Mean Correlation Coefficient (MCC) after optimal matching between ground-truth and learned latents, the regression performance, and an over-complete MCC variant that handles the common case where a model learns more latent dimensions than truly exist.
The authors put a roster of popular CRL approaches through the paces under unmet assumptions, i.e., on scenes that look realistic but don’t line up perfectly with each method’s theoretical prerequisites. In three static scenes (“Ball on the Slope,” “Cylinder Spring,” “Light Refraction”), a supervised “upper bound” that directly learns latents from labels lands near perfect, demonstrating that the encoder capacity isn’t the bottleneck. But unsupervised CRL methods tell a different story: many methods capture some explanatory signals in aggregate, but struggle to recover the precise latent variables one-for-one, which is the level you need for clean causal interpretation.
Temporal CRL proves even tougher. Across two video scenes (“Fall Simple” in physics and a “Robotics Study”), a set of recognized methods post scores that are far from satisfying. The methods that inject sparsity or exploit temporal context do relatively better, but the absolute numbers underline how fragile temporal identifiability can be once you leave toy settings. Tellingly, the robotics scene where relational structure is denser yields somewhat higher results than the simple fall scene, hinting that richer structured signals help, but still not enough to close the gap.
Because CausalVerse is configurable, the authors can also demonstrate why assumptions matter. The “Sufficient Change” principle, for instance, theoretically needs enough distinct “views” (environments) relative to the dimensionality of nuisance factors. When the team constructs a version of the “Cylinder Spring” scene that meets this requirement by adding sufficient domains, MCC jumps markedly, a clean vindication that the math isn’t at fault; the data regime is. Conversely, corrupting domain labels or collapsing to a single scene predictably tanks identifiability, showing how easy it is to fool yourself about causal recovery when the preconditions aren’t satisfied. CausalVerse is the kind of rare benchmark that lets you toggle assumptions and watch the scores move this crisply.
What the results reveal
One way to read these results is pessimistic: causal representation learning, as implemented today, breaks down on complex visuals. A more constructive reading that the authors encourage is that fidelity plus ground truth finally lets us see where it breaks and why. The zero-shot results show that methods relying on sparse mechanisms can help but aren’t magic; temporal identifiability needs stronger sequence signals or architectural priors; multi-view and contrastive strategies recover blocks but not components unless their conditions are met.
With CausalVerse, you can now systematically test fixes: add more domains until “sufficient change” really is sufficient; inject explicit temporal structure; bias encoders with geometry or multi-view consistency; or design hybrid objectives that mix block-wise and component-wise constraints. The benchmark turns hand-wavy advice into experiments you can actually run.
The authors are also clear about the scope and limits. CausalVerse is simulated, not scraped from the wild, and while the visuals are high-fidelity, reality is messier: sensors drift, people behave unpredictably, and causal structure can be ambiguous or contested. Still, for the core CRL question, simulation is how you keep a foot in realism without giving up the ability to grade the test fairly. According to Guagnyi, “Building on these benchmarks, we plan to develop a detailed checklist to systematically evaluate current methods and explore potential practical challenges and solutions.”
If you work on embodied AI, robotics, or safety-critical perception, the value proposition is straightforward. Models that “understand” a scene only in correlative terms will fail in the presence of interventions: new lighting, a different robot policy, a push that changes an object’s momentum. Methods that internalize the causal mechanisms can generalize across those shifts and support planning: what happens if I do this? CausalVerse gives you a way to tell the difference, and to iterate until the answer is something stronger than wishful thinking.
Related

Training multimodal AI with limited labels for a world it has never seen
A new framework from MBZUAI researchers helps AI systems remain effective when data is scarce and inputs.....
Read More
Two heads are faster than one
MBZUAI researchers have developed a new approach to video understanding that reduces computational costs while maintaining accuracy.
- conference ,
- large multimodal model ,
- CVPR ,
- video ,
- research ,

The watermark as combination lock
A new system developed by MBZUAI embeds unique, key-driven watermarks into AI-generated videos, making synthetic content more.....
- watermarks ,
- CVPR ,
- conference ,
- security ,
- computer vision ,
- research ,