
Bridging probability and determinism: A new causal discovery method presented at NeurIPS
Monday, December 23, 2024

Longkang “Loka” Li, a doctoral student in machine learning at MBZUAI, is interested in causal discovery, which seeks to identify causal relationships between variables from data and explain how things in the world influence each other.
Causal discovery has implications for a variety of other disciplines, including biology, economics and public health, where experiments can be expensive, time-consuming, or are simply impossible to conduct in a way that illuminates causal relationships. And while observational data from these disciplines are widely available — for example, economic data published by governments and clinical trial data — this information on its own doesn’t provide much insight about causality.
This is, indeed, the obstacle faced by scientists who work on causal discovery: identifying causal relationships in large and complex datasets with the goal of illuminating how things work. “This world is messy and mysterious,” Li says. “However, we can always find a way to discover the truth and then make desired differences.”
Li, along with colleagues from MBZUAI and other institutions, is co-author of a study that proposes a new method that can be used to identify relationships between what are known as deterministic and non-deterministic variables. The team recently presented their findings at the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), which was held in Vancouver.
Real-world implications
Li is interested in how causal discovery methods can be used for real-world applications, particularly in health care and biology, as gaining a better understanding of the relationships between variables can benefit fundamental scientific research and aid the development of new medicines. “We always want to know more about health and biological processes in humans, yet there are so many aspects of health and biology that we don’t understand,” he says.
Li was motivated to pursue causality not only because it is intellectually interesting, but because of his own experiences. As an undergraduate, he focused on software engineering, but after the loss of a family member to cancer, he decided to dedicate himself to a topic that has practical implications for improving human health. “I was motivated to study causality because it is one of the best ways to identify a reason for a disease,” he says.
Probability vs. determinism
Li and scientists like him who work on causal discovery build what are known as directed graphs that are essentially visualizations of the relationships between and among variables. The nodes of these graphs represent variables and the connections, or edges, as they’re called, represent the causal relationships between them.
Causal discovery frameworks are often built according to probabilistic principles that take into account levels of error, known as noise. In the real world, however, there are relationships that aren’t probabilistic but rather deterministic, meaning that variables may be determined by their direct causes without any uncertainty, Li explains.
An example is body mass index (BMI), which is calculated by dividing a person’s body weight by the square of their height. Because BMI is defined by this set formula, the relationship between weight, height and BMI is deterministic rather than probabilistic, as there’s no random noise that influences the calculation.
While deterministic relationships are common in the real world, they have posed a challenge for causal discovery frameworks based on concepts of probability. Li and his colleagues were therefore motivated to develop a causal discovery method that could deal with deterministic relations.
Common methods in causal discovery
Today there are two main approaches to causal discovery, known as constraint-based and score-based methods. Perhaps the most common constraint-based approach is the PC algorithm, named after the scientists who developed it, Peter Spirtes and Clark Glymour. A common score-based method is called greedy equivalent search.
Constraint-based methods, including the PC algorithm, fail with deterministic relations. This implies that when there is access to more variables which are deterministically related to the original variables, it becomes difficult to identify causal relations. However, intuitively, with more observed variables, researchers should be able to discover more causal knowledge. Inspired by this expectation, with a slight modification to greedy equivalent search, Li and his colleagues found that they were able to develop an approach that worked with deterministic relations.
The scientists call their technique determinism-aware greedy equivalent search, and it moves in three steps. First, they identify clusters of variables that have deterministic relationships by exploring if a variable can be “minimally determined by some other variables.” Second, they run a greedy equivalent search on all the variables to obtain an initial graph of their relationships. Third, they perform what is known as an exact search only on the deterministic clusters and their neighbors.
The approach separates data into three different groups: deterministic clusters, non-deterministic clusters. and bridge sets, which separate the two kinds of clusters. The entire causal graph can be divided into these three categories, Li and his colleagues note in the study.
The researchers compared their determinism-aware greedy equivalent search to other approaches, including PC and greedy equivalent search. They found that theirs performed better than PC and greedy equivalent search across several different criteria and settings on a synthetic dataset. They found, however, that when there are more deterministic clusters in a dataset, the time needed to run their algorithm increases because there are more relationships that need to be analyzed through exact search, which is computationally intensive.
Real-world dataset
Li and his colleagues also tested their approach on a real-world dataset taken from clinical studies that provides information about how people processed medicines. There are three kinds of information in the dataset: characteristics of patients, such as height and weight; information about drugs, such as how they were administered and the dose; and measurement records, which relate to how quickly a patient’s body processed a drug.
Li and his colleagues’ method was able to detect three deterministic clusters in the data — other methods weren’t able to do this. For example, the team’s technique identified relationships between height, weight and BMI while also maintaining these variables’ connections to other non-deterministic variables. “This is quite meaningful,” Li explains, “because using our method we can maintain the meaningful edges between variables.” With other approaches, the edges between the deterministic variables and the non-deterministic variables would disappear.
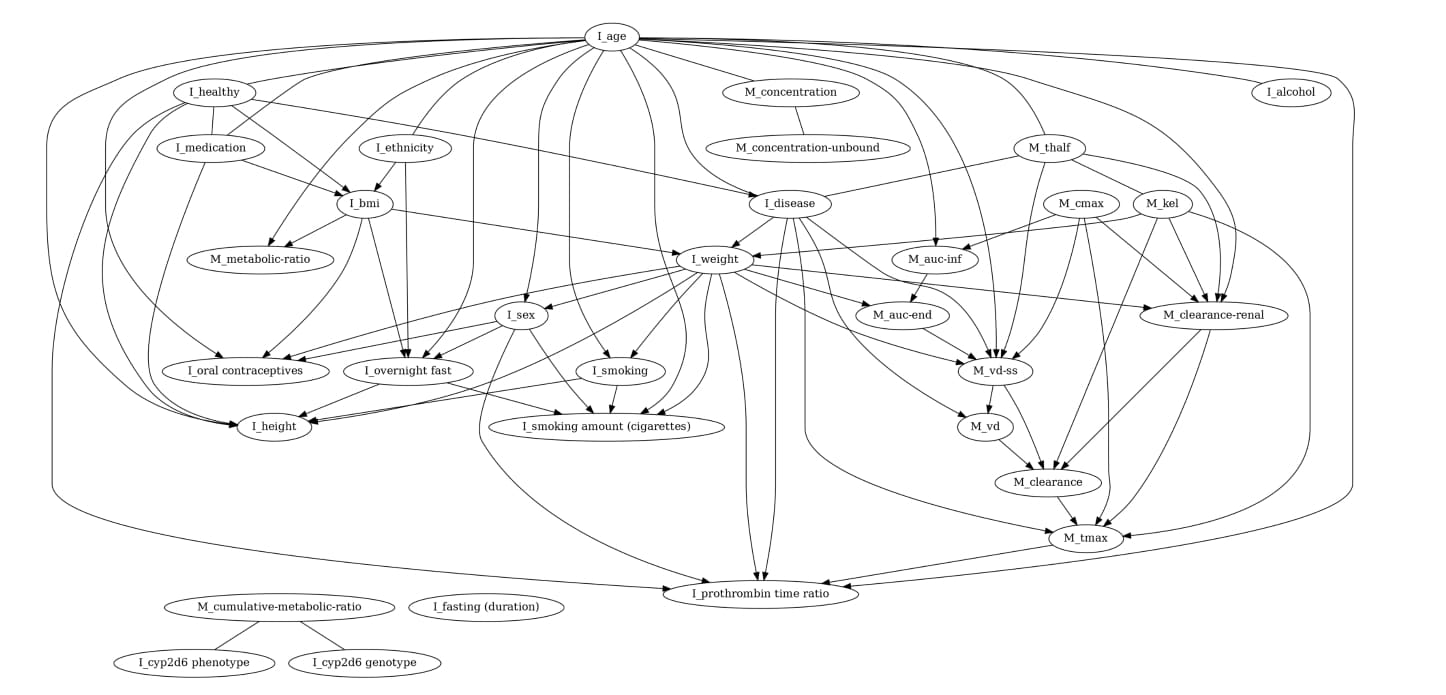
A new causal discovery method, determinism-aware greedy equivalent search, was developed to identify both deterministic and non-deterministic relationships between variables in a real-world dataset composed of clinical trial data. This had been a challenge for previous methods.
New problems to solve
In the future, Li said that he hopes to enhance determinism-aware greedy equivalent search so that it can achieve full identifiability among the deterministic variables by incorporating more assumptions.
He also explains that while he and the rest of the team may have solved one problem related to deterministic relationships in real-world data, there are many problems out there waiting to be solved, including difficulties that relate to measurement errors, which are common with real-world datasets.
Looking forward, he is considering how the insights developed creating determinism-aware greedy equivalent search could be combined with new approaches to deal with measurement errors. “We could combine several challenges together and see how we could solve them in real-world datasets,” he says.
- machine learning ,
- research ,
- neurips ,
- casual discovery ,
- variables ,
- determinism ,
- student ,
Related

The watermark that wasn't there
A new technique from MBZUAI researchers removes AI image watermarks in seconds – exposing potential weaknesses in.....
- watermark ,
- watermarking ,
- CVPR ,
- computer vision ,

Solving a fundamental problem in causal discovery
A new approach led by MBZUAI helps researchers identify which causal relationships can truly be recovered from.....
- research ,
- ICLR ,
- conference ,
- causal discovery ,
- machine learning ,

Redesigning a classic multimodal learning tool for the age of distributed data
A new framework from MBZUAI researchers enables institutions to uncover shared patterns across datasets while keeping sensitive.....
- framework ,
- AISTATS ,
- machine learning ,
- datasets ,
- research ,
- multimodal ,
- ML ,
- conference ,